How to Reduce Technical Debt A Practical Guide for Modern Teams

Tackling technical debt is more than a simple cleanup project. It’s a strategic shift in how your team thinks about and maintains the long-term health of your software. This means systematically finding the problems, figuring out what to fix first based on business impact, doing the work, and then putting new processes in place to keep it from piling up again.
The True Cost of Technical Debt on Your Business

Technical debt isn't just about messy code. It's a silent killer of growth that quietly eats away at your budget, stifles innovation, and burns out your best engineers. It might start in the codebase, but its effects spread throughout the entire company, slowing down product releases and hurting customer satisfaction.
Think of it like financial debt—if you don't manage it, the "interest payments" spiral out of control. Your team ends up spending all their time putting out fires and patching together complex workarounds instead of building valuable new features. This creates a vicious cycle where every new project is slower and harder than the last, directly hampering your ability to stay competitive.
From Hidden Costs to Tangible Losses
The financial toll is often much larger than anyone realizes. In many companies, a significant chunk of the tech budget gets secretly funneled into dealing with the fallout from old shortcuts. This isn't just about lost productivity; it's about the very real cost of missed market opportunities and stunted growth. To get a handle on these numbers and build a strong case for investing in fixes, it helps to apply a structured approach like the one outlined in this Cost Benefit Analysis For Software A Practical Guide.
The data tells a stark story. A McKinsey report highlights that 30% of CIOs admit that over 20% of their new-product tech budgets are rerouted to deal with technical debt issues. But there's a huge upside to addressing it: paying down that debt can free up engineering teams to spend up to 50% more of their time on work that actually creates value.
Connecting Code Health to Business Outcomes
The real challenge is often helping non-technical stakeholders see how code-level problems directly impact business goals. The table below draws a clear line between the symptoms developers see and the pain the business feels.
Technical Debt Symptoms and Business Impact
| Symptom | Technical Indicator | Business Impact |
|---|---|---|
| Slow Development Velocity | High cyclomatic complexity, lack of modularity, tightly coupled components. | Delayed feature releases, inability to react to market changes, lost competitive advantage. |
| Increased Bug Rate | Low test coverage, inconsistent error handling, fragile code. | Poor user experience, customer churn, damaged brand reputation, increased support costs. |
| High Onboarding Time | Poor or outdated documentation, complex build processes, no clear architecture. | Reduced team productivity, higher training costs, slower team growth. |
| System Instability | Frequent outages, performance bottlenecks, memory leaks. | Lost revenue due to downtime, SLA penalties, decreased customer trust. |
Seeing these connections makes it clear that managing technical debt isn't just an expense—it's a critical investment in your company's future agility and success. When you can frame the conversation around business outcomes, you're no longer just talking about "cleaning up code"; you're talking about building a more resilient and profitable business.
How to Diagnose and Measure Your Technical Debt

You can't fix a problem you can't see. Vague feelings like "our app feels clunky" won't convince anyone to invest in a solution. To really tackle technical debt, you have to move past gut feelings and start measuring things concretely.
The goal here is to turn those abstract code issues into hard, quantifiable data. This diagnostic phase is all about gathering the evidence you need to build a compelling business case, justifying the time and resources required to pay down your debt. It sets the stage for everything that comes next.
Start with a Code Audit and Static Analysis
First things first, you need an objective look at your codebase's health. This is where static analysis tools are a lifesaver. Tools like SonarQube, CodeClimate, or even simpler linters like ESLint scan your code without actually running it, flagging common red flags for technical debt.
Think of these tools as an impartial, automated code reviewer that never gets tired. They're brilliant at catching things like:
- Code Smells: These are patterns that hint at deeper design problems. Think of methods that are way too long or classes trying to do ten different things at once.
- Duplicated Code: Copy-pasted logic is a ticking time bomb. When you fix a bug in one place, you have to remember to fix it everywhere else it was pasted, which is a recipe for disaster.
- High Cyclomatic Complexity: This is a fancy term for convoluted, spaghetti-like code. A high score means the logic has too many paths, making it a nightmare to understand, test, and maintain.
These tools will give you a baseline report—a snapshot of where you stand today. This initial data is your starting point for turning those vague concerns into a targeted hit list.
Calculate Your Technical Debt Ratio
While static analysis points out specific problems, the Technical Debt Ratio (TDR) gives you a big-picture number that helps quantify the total effort needed. It's a high-level metric that’s surprisingly effective at getting both technical and non-technical stakeholders on the same page.
The Technical Debt Ratio is simple: it compares the cost to fix the codebase (Remediation Cost) with the original cost to build it (Development Cost). A lower ratio is always better.
The formula is pretty straightforward:
TDR = (Remediation Cost / Development Cost) x 100
Here, "cost" is usually measured in developer-days or hours. For instance, if SonarQube estimates it would take 20 days to fix all the issues in a codebase that took 200 days to build, your TDR is 10%. This single number is a powerful tool for communicating the scale of the problem and tracking your progress over time.
Listen to Your Team and Your System
Data is crucial, but it never tells the whole story. To get a complete diagnosis, you need to pair the quantitative metrics with qualitative insights from your developers and your system's actual performance.
Developer Feedback
Your engineers are in the trenches every day; they know where the bodies are buried. The key is to create a safe environment where they can be honest about the parts of the system they absolutely dread working on.
Try asking some pointed questions:
- Which module is the most fragile and seems to break with every new feature?
- What part of the codebase takes a new hire the longest to get their head around?
- If you had a full week to refactor anything, no questions asked, what would it be and why?
This kind of feedback points you directly to the biggest sources of friction and the things that are actively killing your development velocity.
Application Performance Monitoring
Finally, look beyond the code itself to how your debt is impacting the user experience. You can find some great strategies in our guide to application monitoring best practices. APM tools can help you trace performance bottlenecks, flag slow database queries, and identify recurring errors that are often symptoms of poor underlying code quality.
A classic example is a mobile app that takes forever to load. An APM tool might trace that sluggishness back to an old, inefficient third-party library—a perfect example of technical debt. By connecting the dots between code metrics and real-world performance data, you build a comprehensive report that links technical problems directly to their business impact.
A Practical Framework for Prioritizing What to Fix
Once you've cataloged your technical debt, the temptation is to jump right in and start fixing everything. That's a mistake. A scattergun approach to refactoring is nearly as bad as ignoring the problem altogether—it burns through precious engineering time without delivering predictable business value.
The real key is to shift from a chaotic, "fix-it-all" mindset to a structured, strategic one. You need a practical way to decide what gets tackled now, what's scheduled for later, and what you can safely live with for the time being. This is how you start making defensible decisions that align your engineering efforts with what actually matters to the business.
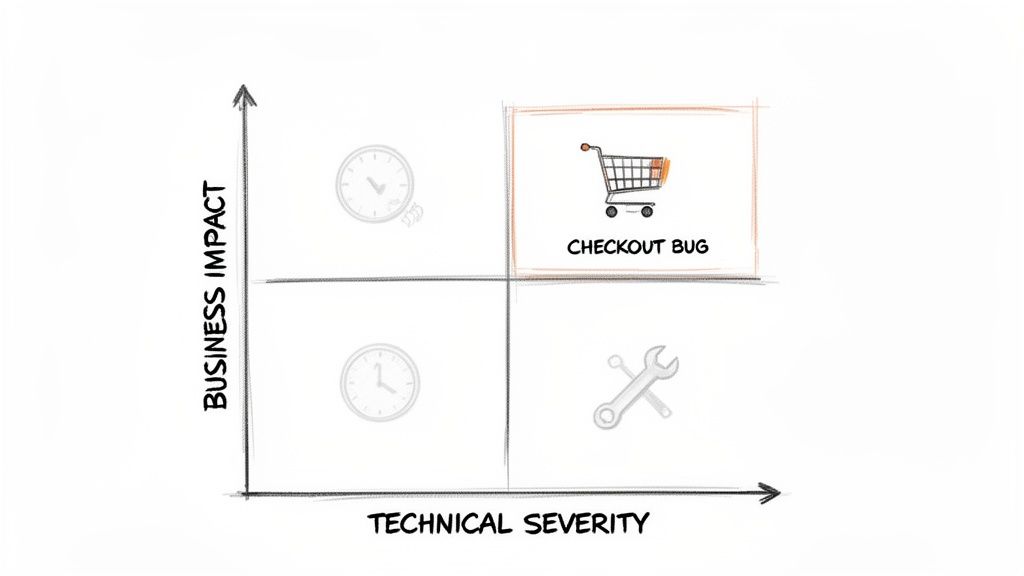
Balancing Business Impact and Technical Severity
The most effective way I’ve found to do this is with a simple two-axis matrix. This isn't just about making a pretty chart; it's a powerful tool for forcing a conversation about two critical dimensions for every piece of debt:
- Business Impact: How much does this hurt users, revenue, or strategic goals? Think of it this way: a bug in the checkout flow is a massive deal, while a clunky internal admin panel is an annoyance.
- Technical Severity: What’s the damage to the system's health? A critical security vulnerability is obviously high severity. Some duplicated code in a non-critical utility function? Much, much lower.
When you start plotting your issues on this matrix, you get a visual guide that instantly clarifies your priorities. This isn't just for engineers, either. It’s a communication tool that brings product managers and other stakeholders into the loop, making sure everyone agrees on what "important" really means.
The Four Quadrants of Prioritization
Your matrix will naturally break your debt into four distinct categories, and each one demands a different response.
1. High Impact, High Severity (Fix Immediately)
These are your true five-alarm fires. They are actively harming your users, costing you money, and making your system unstable.
- Real-World Example: A critical security flaw in your user authentication service that could expose customer data.
- Your Action: Drop everything. This is non-negotiable and requires an immediate fix.
2. High Impact, Low Severity (Schedule It)
This kind of debt is a major source of pain for customers or internal teams, but it isn't an immediate threat to system stability. It’s the "death by a thousand cuts" stuff.
- Real-World Example: A convoluted and painfully slow reporting feature that key customers rely on daily. It works, but it generates endless support tickets.
- Your Action: This gets planned and scheduled for an upcoming sprint. It has a clear business case and deserves a proper project plan.
3. Low Impact, High Severity (Contain and Monitor)
Here you’ll find the ticking time bombs—the underlying architectural problems that aren't affecting users yet but could cause a catastrophe down the line.
- Real-World Example: An outdated and unsupported core library that no longer gets security patches.
- Your Action: Isolate the problem to keep it from spreading. Plan a project to replace it, but it doesn't need to bump more urgent, user-facing work.
4. Low Impact, Low Severity (Accept or Backlog)
This is your "good enough for now" bucket. These issues are minor annoyances with a negligible effect on both the user and the system's health.
- Real-World Example: Inefficient code in an internal-only script that runs once a month.
- Your Action: Toss it on the long-term backlog or, even better, formally decide to accept it as-is. Don't let your team waste time here.
By prioritizing visibility through dashboards and KPIs, engineering teams can avoid the staggering 61 billion days of global repair time spent on these issues. This isn't just cleanup; it's a strategic investment that leads to faster deployments and a better user experience. Discover more insights on managing technical debt from Oteemo.
Ultimately, a solid prioritization framework transforms the abstract challenge of "technical debt" into a series of clear, actionable, and data-driven decisions. It ensures your team is always working on the fixes that deliver the most value, protecting both your product and your bottom line.
Executing Your Plan With Smart Refactoring
You’ve done the hard work of identifying and prioritizing your technical debt. Now, with a solid roadmap in hand, it's time to roll up your sleeves and start making a dent. This is where the rubber meets the road—where your strategy becomes reality.
This phase isn't about massive, risky rewrites. It's about making smart, targeted changes that deliver real improvements without grinding your product development to a halt. The goal is to adopt a refactoring mindset.
Think of it like this: refactoring is the art of restructuring your code to improve it internally without changing what it does on the outside. You’re not adding features; you're making the code cleaner, more efficient, and a whole lot easier for your team to work with in the future.
Choose the Right Refactoring Strategy
You wouldn't use a sledgehammer to hang a picture frame. In the same way, the refactoring technique you choose must fit the problem you're trying to solve. Applying a massive architectural pattern to fix a minor "code smell" is overkill and wastes precious time.
Your choice of strategy should always match the scale and type of debt you're tackling. Here are a few battle-tested techniques that work for everything from quick cleanups to major system overhauls.
Extract Method: This is probably the most common—and powerful—move in the refactoring playbook. You see a long, clunky method that’s trying to do three different things at once? Pull out a logical chunk of that code and give it its own new, well-named method. This immediately makes the code easier to read and reuse.
Rename Variable/Method: Never underestimate the power of clear naming. A variable called
xor a method namedhandleStuff()is a ticking time bomb of confusion. Renaming them to something descriptive likecustomerAccountBalanceorcalculateShippingCosts()instantly clarifies intent and saves the next developer a major headache.Strangler Fig Pattern: When you're facing a massive, monolithic legacy system, a full rewrite is usually off the table—it’s just too risky. The Strangler Fig Pattern is a much safer path forward. You incrementally build new services around the edges of the old system, gradually intercepting requests and routing them to the new, modern code. Eventually, the old system is completely "strangled" and can be safely retired. We cover more approaches like this in our guide to legacy system modernization strategies.
A classic mistake is to treat refactoring like a separate, isolated project. The best teams weave it directly into their daily work. They live by the "leave it better than you found it" rule, where every developer makes small, constant improvements. This prevents debt from ever piling up into a crisis in the first place.
Choosing the right tool for the job is essential. Here’s a quick guide to matching common refactoring techniques with the problems they solve best.
Common Refactoring Strategies and When to Use Them
| Refactoring Technique | Best For | Example Scenario |
|---|---|---|
| Extract Method | Reducing complexity in long, convoluted functions. | A 150-line generate_report() function has distinct sections for fetching data, formatting it, and emailing it. Each section can be extracted into its own method. |
| Introduce Parameter Object | Simplifying method signatures that have too many parameters. | A method call like createUser(name, email, pass, dob, addr, city, zip) becomes createUser(userDetails). |
| Strangler Fig Pattern | Incrementally replacing a large, legacy monolithic system. | A legacy e-commerce platform's payment processing module is replaced with a modern microservice that intercepts all payment-related API calls. |
These techniques, when applied correctly, can methodically chip away at even the most daunting backlogs of technical debt.
Bolster Your Team for the Big Push
What happens when the refactoring effort is just too big for your current team to handle without stopping all new feature development? It's a classic bottleneck that forces a painful choice between innovation and stability.
This is where strategic team augmentation can be a total game-changer.
Bringing in a nearshore staff augmentation team gives you the focused, expert firepower needed to execute a major refactoring project. This dedicated squad can work in parallel with your core team, systematically crushing the debt backlog while your developers keep shipping features that your customers love.
This parallel approach has some clear wins:
- Maintain Momentum: Your product roadmap doesn't get put on hold. The nearshore team acts as your dedicated "debt repayment" crew.
- Specialized Skills: You get instant access to developers who specialize in modernization, like migrating tricky legacy codebases or implementing complex architectural patterns.
- Cost-Effectiveness: Nearshore teams offer a pipeline to world-class talent in compatible time zones, often at a more competitive cost than hiring locally for a short-term project.
By bringing in outside experts, you transform a potentially disruptive internal project into a manageable, parallel workstream. You get to pay down your technical debt without sacrificing your competitive edge.
Building a Culture That Prevents Future Debt

Fixing the tech debt you have now is a huge win, but it’s only half the battle. If you don't address the habits that created the mess in the first place, you'll be right back where you started in a year. The real goal is to build a culture where quality is a shared responsibility, not just a line item to be dealt with later.
This kind of change has to start at the top. Getting leadership buy-in is absolutely essential, and the trick is to stop talking about "clean code" and start talking about business risk. Frame the conversation around the real-world costs of neglect: slower feature releases, a spike in bug reports, and your best engineers spending their time putting out fires instead of innovating.
Establish Clear Guardrails for Quality
To stop future debt from piling up, you have to define what "good" actually looks like. Ambiguity is the enemy of quality. Without clear standards, every developer has their own interpretation, and that's a fast track to inconsistency and future maintenance nightmares.
Start by documenting clear coding standards. This isn't about micromanaging; it’s about creating a shared language for quality. These guides should cover everything from naming conventions and formatting to error handling and API design. Even better, automate enforcement with linters and formatters in your CI/CD pipeline so following the rules becomes effortless. For infrastructure specifically, adopting modern approaches like Infrastructure as Code Best Practices can build quality in from the ground up.
Another fantastic tool here is the Architecture Decision Record (ADR). An ADR is just a simple document that captures a key architectural decision—the context, the options you weighed, and why you made the final call. This creates an invaluable history that helps new developers understand why the system is built the way it is, preventing them from accidentally introducing debt by breaking a core design principle.
Promote Ownership and Continuous Improvement
A culture of quality can only thrive when teams feel a real sense of ownership over their work. When engineers are truly responsible for the code they ship, they naturally become more invested in its long-term health. The "you build it, you run it" mindset is a powerful way to make this happen.
When developers are on the hook for deploying, monitoring, and supporting their own code in production, they feel the pain of their own shortcuts immediately. This creates a tight feedback loop that encourages them to build more robust, maintainable, and well-tested software from the get-go. The focus shifts from just "closing a ticket" to delivering a truly reliable solution.
One of the most effective habits I've ever seen in high-performing teams is the "Boy Scout Rule"—always leave the code a little cleaner than you found it. It’s a simple principle, but when applied consistently, it turns every single commit into a small act of debt repayment and prevention.
This idea of continuous improvement needs to be woven directly into how you work. Many successful teams find that the core principles of agile software development best practices provide an excellent foundation for this.
Make Maintenance a Routine, Not a Reaction
Ultimately, the most practical way to stop debt from accumulating is to make paying it down a regular, scheduled activity. Waiting for a "stabilization sprint" or a "refactoring week" is a recipe for failure; those are always the first things to get axed when a deadline is looming.
A much more sustainable approach is to set aside a fixed percentage of every sprint for maintenance and debt reduction.
- Create a "Quality Budget": Dedicate 15-20% of each sprint's capacity to non-feature work. This bucket includes refactoring, upgrading libraries, improving tests, and knocking out small pieces of tech debt.
- Treat It as a Rule: This isn't "nice-to-have" time. This allocation is a non-negotiable part of your team's capacity—a critical investment in your future speed.
- Make It Visible: Track this work on your project boards and report on it just like you do for new features. This reinforces its importance and shows a real, ongoing commitment to code health.
By making maintenance a consistent part of your workflow, you transform debt repayment from a massive, painful project into a manageable, ongoing habit. This proactive stance is the cornerstone of a culture that doesn't just fix tech debt but actively stops it from taking root.
Navigating the Tough Questions About Technical Debt
Creating a plan to tackle technical debt is the easy part. The real test comes when you have to get buy-in, allocate resources, and answer the hard questions from stakeholders. It’s where the rubber meets the road.
Let's walk through some of the most common challenges you'll face and how to handle them like a pro.
How Do I Get My Non-Technical Manager to Care About This?
This is probably the biggest hurdle for most engineering teams. The secret is to stop talking about technology and start talking about business impact. Your manager might not know what a database schema is, but they definitely care about revenue, customer churn, and how productive the team is.
You have to translate the technical problem into their language.
Instead of saying, "We need to refactor the authentication service," frame it as a business opportunity. Try something like this: "If we spend the next two sprints improving our authentication service, we can cut login failures by 50%. Our support team currently spends 10 hours a week on login-related tickets, so we’d be freeing them up and improving the new user experience."
See the difference? It's no longer a cost center; it's a direct investment in customer satisfaction and operational efficiency.
Analogies work wonders here. I often compare technical debt to financial debt—the longer you let it sit, the more "interest" you pay in the form of bugs, slowdowns, and frustrated developers. Show them the data. Pull up a chart that illustrates how much time the team is burning on preventable issues instead of building that new feature the sales team has been asking for.
Pro Tip: Propose a small pilot project. Find one piece of debt that's a known pain point and scope out a quick-win refactor. When you can come back in two weeks and show a measurable improvement, you'll have all the credibility you need for a bigger investment.
This reframes the entire conversation from a technical chore to a smart, strategic decision.
Isn't All Technical Debt Bad?
Not at all. Just like financial debt, there’s a world of difference between a strategic loan and reckless spending. Understanding this distinction is key to making intelligent trade-offs.
Good technical debt is a conscious, strategic decision. Let's say a competitor is about to launch a killer feature, and you need to get your version to market first. You might deliberately cut a few corners to hit that deadline, fully aware of the trade-off. You accept the "debt" because the business value of speed is worth the future cleanup cost.
This kind of debt is always:
- Intentional: Everyone on the team knows the shortcut is being taken and why.
- Documented: You create a ticket to fix it before you even ship the code.
- Temporary: There's a clear plan to pay it back in the next quarter.
Bad technical debt, on the other hand, is just plain sloppiness. It’s the messy, undocumented code that happens from rushing, inexperience, or a lack of clear standards. It’s the debt that sneaks up on you, causing unexpected outages and grinding productivity to a halt without ever providing an upfront benefit.
Can We Use Nearshore Teams to Help With This?
Absolutely. In fact, bringing in a specialized nearshore team can be a brilliant move, especially if you have a mountain of debt to clear. Think of them as a dedicated crew that comes in to handle the renovations while your core team continues building the main product.
This approach is a game-changer for big refactoring initiatives or modernizing a legacy system. While your in-house engineers are focused on shipping new features that customers are clamoring for, the nearshore team can dive deep into the cleanup work without distraction.
Because they operate in similar time zones, you get smooth collaboration without the late-night calls or communication lags common with traditional offshore models. It's a fantastic, cost-effective way to get focused expertise exactly where you need it, freeing up your star players to innovate.
How Much of Our Sprint Should We Spend on Tech Debt?
There's no single magic number, but a great rule of thumb that I've seen work time and again is allocating 10-20% of each sprint's capacity to paying down debt.
The key here is consistency. Don't wait for a "tech debt sprint" that never comes. Instead, make it a regular, predictable part of your development rhythm. It's like brushing your teeth—a small, daily habit that prevents massive problems down the line.
When you continuously chip away at the backlog, you keep the codebase healthy and your team's velocity predictable. This small, steady investment is one of the best things you can do for your long-term agility and team morale.